【python爬虫案例】利用python爬取豆瓣电影TOP250评分排行数据!
一、爬取对象-豆瓣电影TOP250
今天给大家分享一期豆瓣读书TOP排行榜250的python爬虫案例
爬取的目标网址是:https://movie.douban.com/top250
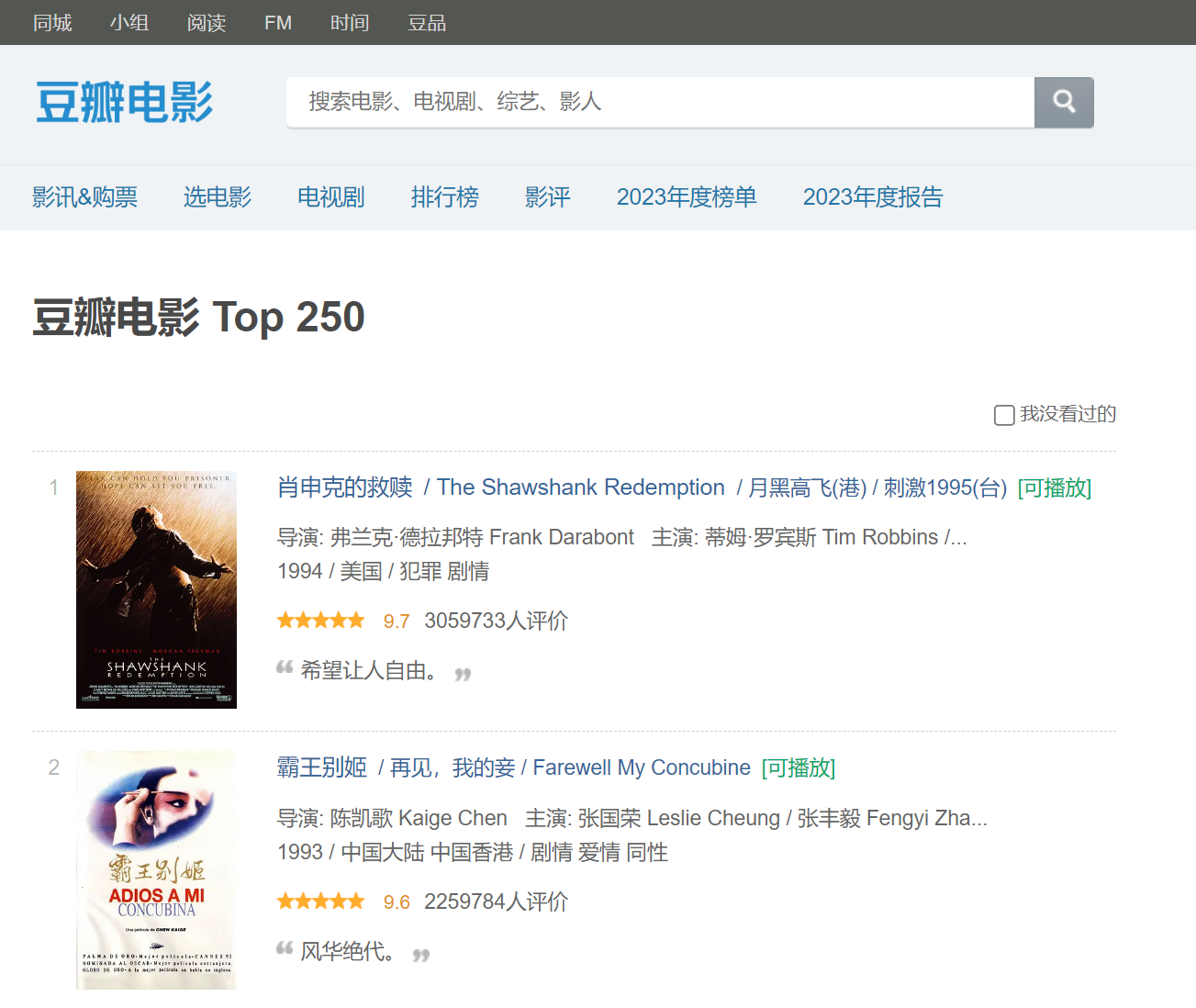
咱们以目标为驱动,以兴趣为导向,先来看下爬虫程序运行后得到的excel文档数据
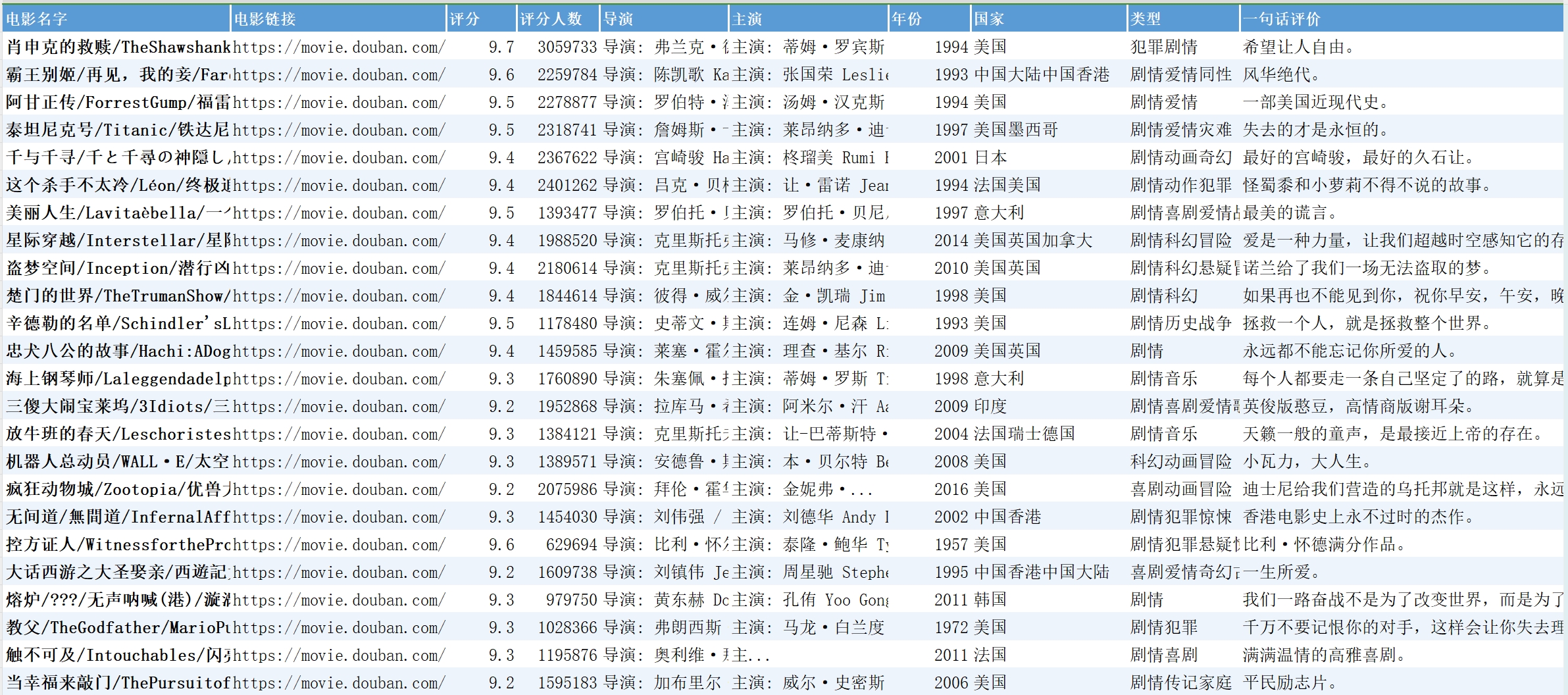
那代码是如何实现豆瓣电影TOP250数据爬取的了?下面逐一讲解一下python实现。
二、豆瓣电影网站分析
通过浏览器F12查看所有请求,发现他并没有发送ajax请求,那说明我们要的数据大概率是在html页面内容上。
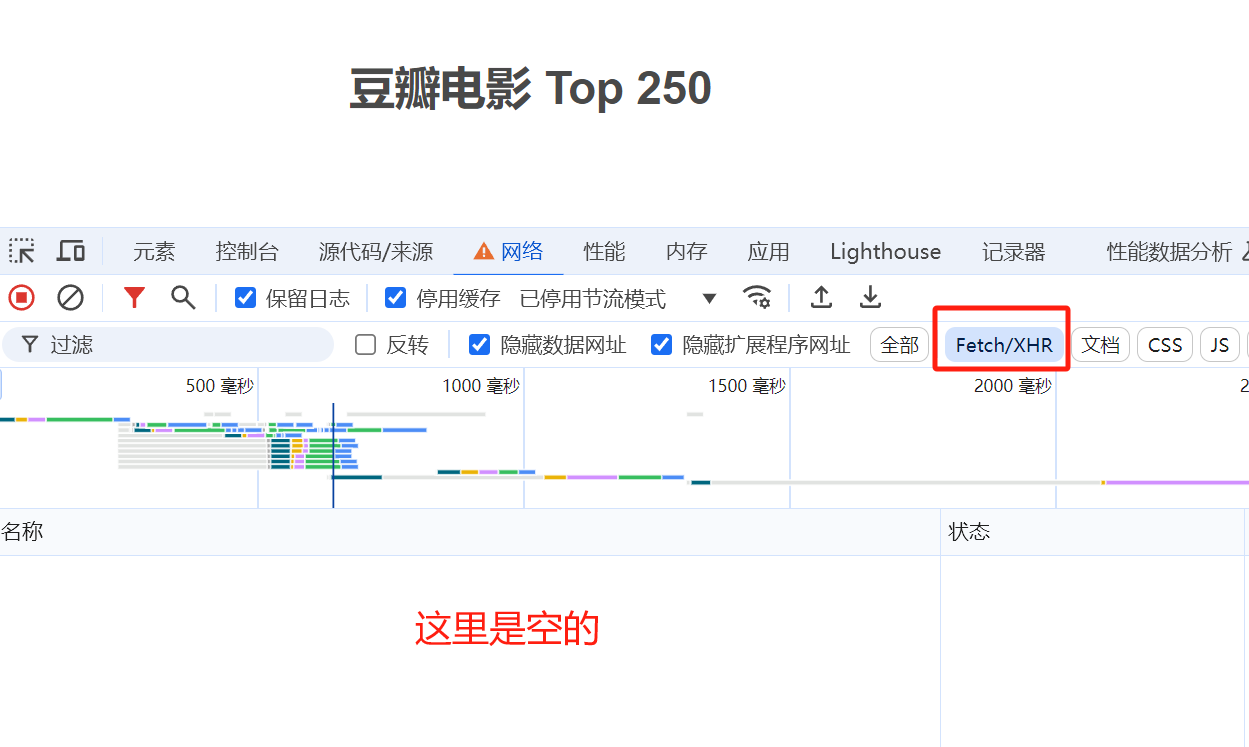
于是我们 点击右键->查看网页源代码 ,发现我们需要的豆瓣电影评分的排行榜数据都在html页面里

这就简单了,我们直接往下看,上代码。
三、python爬虫代码详解
首先,导入我们需要用到的库
import requests # 发请求
from lxml import etree # 解析html
import pandas as pd # 存取csv
from urllib.parse import urljoin # url处理
然后,向豆瓣电影TOP250的网页发起请求,获得html页面内容
page_source = requests.get(page_url, headers=headers).text
用lxml库解析html页面
tree = etree.HTML(page_source)
使用xpath来提取我们需要的排行榜数据内容
# 获得数据所在的标签
lis = tree.xpath("//ol[@class='grid_view']/li")
# 循环标签获得电影信息
for li in lis:
url = extract_first(li.xpath(".//div[@class='hd']/a/@href")).strip() # 链接
movie_name = "".join(li.xpath(".//div[@class='hd']/a//text()")) # 电影名字
movie_name = re.sub("\s+", "", movie_name)
score = extract_first(li.xpath(".//span[@class='rating_num']/text()")).strip() # 评分
star_people_num = extract_first(li.xpath(".//div[@class='star']/span[4]/text()")).strip() # 评价人数
star_people_num = re.search("\d+", star_people_num).group()
one_evaluate = extract_first(li.xpath(".//p[@class='quote']/span/text()")).strip() # 一句话评价
info = "".join(li.xpath(".//div[@class='bd']/p/text()")).strip() # 电影信息:导演、主演、年份、国家、类型
infos = info.split("\n")
director = infos[0].split("\xa0\xa0\xa0")[0] # 导演
actor = None
try:
actor = infos[0].split("\xa0\xa0\xa0")[1] # 主演
except:
# 只有导演,没有主演的(比如 第3页 窃听风暴)
pass
其中,需要特殊说明的是,第3页《窃听风暴》这部电影和其他电影页面排版不同:
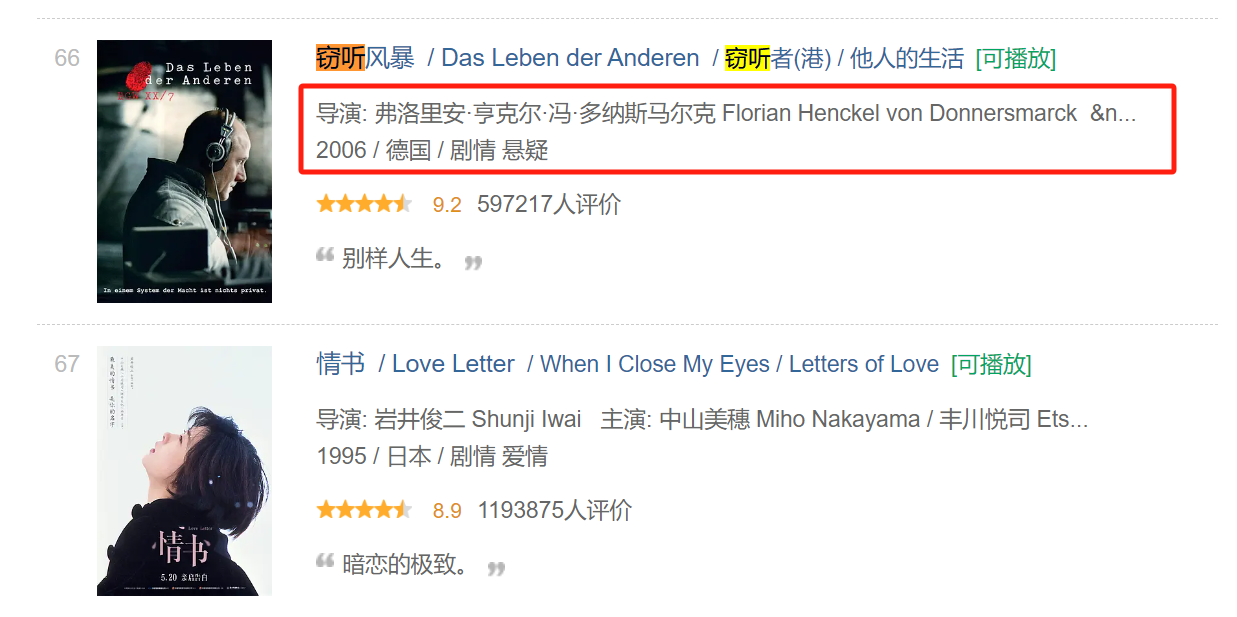
这部电影只有导演,却没有主演信息,所以会有个异常处理的代码
try:
actor = infos[0].split("\xa0\xa0\xa0")[1] # 主演
except:
# 只有导演,没有主演的(比如 第3页 窃听风暴)
pass
还有就是有些电影,他的年份、国家、类型的格式有细微的不同之处,所以也需要特殊处理一下。
info_sub = re.sub("\s+", "", infos[1])
info_subs = info_sub.split("/")
if len(info_subs) == 3:
year = info_subs[0] # 年份
country = info_subs[1] # 国家
type = info_subs[2] # 类型
elif len(info_subs) == 4:
year = str(info_subs[0]) + "/" + str(info_subs[1]) # 年份
country = info_subs[2] # 国家
type = info_subs[3] # 类型
else:
print(f"!!!!未匹配上规则!!!! 电影名称={movie_name}", infos)
最后,我们将爬虫爬取的数据保存到csv文档里
def save_to_csv(csv_name):
"""
数据保存到csv
@param csv_name: csv文件名字
@return:
"""
df = pd.DataFrame() # 初始化一个DataFrame对象
df['电影名字'] = movie_names
df['电影链接'] = urls
df['评分'] = scores
df['评分人数'] = star_people_nums
df['导演'] = directors
df['主演'] = actors
df['年份'] = years
df['国家'] = countrys
df['类型'] = types
df['一句话评价'] = one_evaluates
df.to_csv(csv_name, encoding='utf8', index=False) # 将数据保存到csv文件
print("保存文件成功", csv_name)
上面的movie_names、urls等变量都是使用的list来进行存储的,这样才能符合pandas导出数据时的需要,最后调用to_csv()方法即可导出豆瓣电影的排行榜数据到文档里了。
三、python爬虫源代码获取
我是 @王哪跑,持续分享python干货,各类副业软件!
附完整python源码及数据:【python爬虫案例】利用python爬虫爬取豆瓣电影评分TOP250排行数据!